O estudo do modelo estratigráfico é de suma importância para o estudos de reservatórios. Através desse modelo, podemos definir sequencias geológicas dentro dos hidrocarbonetos. É fundamental que esse estudo seja preciso, já que os fluidos são fortemente influenciados pela geometria interna dos reservatórios. Por isso, para serem obtidos resultados eficientes, é necessário dedicação de tempo e recursos.
Algumas dificuldades que podem ser encontradas no estudo de reservatórios estão relacionadas com o ambiente deposicional. Quando as sequencias sedimentares apresentam uma extensão lateral significativa, as correlações também são relativamente mais simples. Temos alguns exemplos que podemos observar como em alguns campos do Adriático, onde podemos correlacionar eventos individuais de apenas alguns centímetros de espessura mesmo entre poços com vários quilômetros de distância.
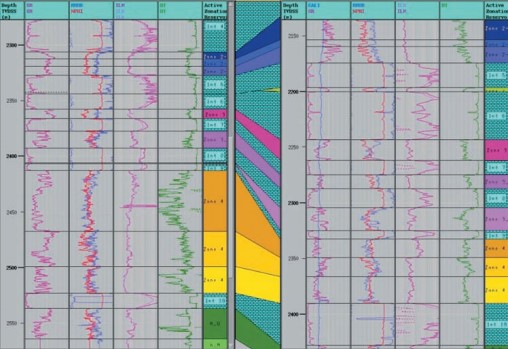
Porém, existem casos em que a extensão lateral dos corpos sedimentares e a distância entre os poços é menor. Esses casos são mais comuns nas formações geológicas continentais e transicionais, como nas aluviais, fluviais e deltaicos, onde reconstruir a geometria interna nos reservatórios pode ser um grande desafio para os geólogos e engenheiros.
A interdisciplinaridade entre os ramos de estudos e o conhecimento de técnicas específicas sobre o assunto são essenciais para aprimorar a precisão do resultado final. Como exemplo, é importante citar a utilização dos dados básicos usados para a relação poço a poço. São registrados logs em poços abertos ou poços revestidos e núcleos para criar seções estratigráficas e correlações, em termos de profundidade real ou nível de referência através do qual podemos geralmente identificar as linhas das variações correspondentes.
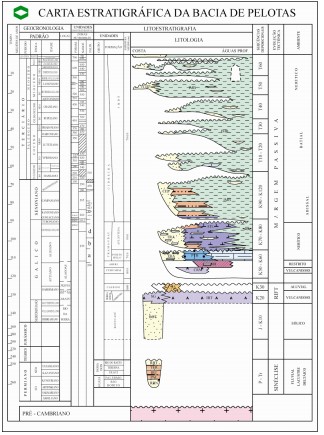
Fig. 2. Carta cronoestratigráfica da Bacia de Pelotas
O sistema cronoestratigráfico pode ser um importante aliado dos geólogos e engenheiros a fim de evitar possíveis erros. Este tem como base a hipótese de que a deposição de corpos sedimentares está diretamente relacionada com os efeitos das mudanças no nível do mar, sedimentação, subsidência e tectônica.
Dessa forma, é possível identificar sequências de diferentes ordens hierárquicas dentro de uma unidade geológica. Essas sequências representam as inconformidades ou superfícies de alagamento máximo. A correta identificação vai gerar um trabalho cronoestratigráfico extremamente detalhado.

Após definir a correlação de referência, é interessante analisar a precisão usando outras técnicas e dados, como:
• Bioestratigrafia e palinologia – exemplos de rochas são analisados com o objetivo de estudar a micropaleontologia e/ou associações palinológicas.
• Dados de pressão – com esses dados é possível obter importantes informações sobre a continuidade e conectividade de vários corpos sedimentares.
• Dados de produção – A observação do equilíbrio termodinâmico correspondente com características específicas dos fluidos produzidos na superfície (razão gás-óleo e densidade do óleo). A presença de anomalias pode indicar problemas de correlação.
• Dados de perfuração – a taxa de penetração fornece informações úteis sobre a estrutura estratigráfica cruzada. Esses dados fornecidos pela atividade de perfuração podem ser usados para verificar a consistência das correlações.
Com os horizontes estratigráficos definidos nos poços durante a fase de correlação, eles são ligados um ao outro, construindo superfícies que, juntas, formam modelo estratigráfico do reservatório. Este modelo consiste em uma série de mapas de espessura dos horizontes geológicos individuais localizados entre as superfícies de limite superior e inferior do reservatório. O modelo tridimensional é o mais usado por geólogos de reservatório para modelagem estratigráfica.
Então, é definida a geometria interna, para criar o conjunto de superfícies entre o topo e o fundo do reservatório que representam os limites entre as sequências geológicas selecionadas para correlação. Geralmente, como já enfatizado, estas superfícies formam limites entre unidades de fluxo que são independentes uma da outra.
Por Bruno Fischer
Referências
COSENTINO, Luca. Integrated Reservoir Studies. Paris : Editions Technip, 2001.
BARBOZA, E.G. Cronoestratigrafia da Bacia de Pelotas: uma revisão das sequências deposicionais. GRAVEL, Porto Alegre, junho, 2008. Disponível em: https://www.ufrgs.br/gravel/6/1/Gravel_6_V1_09.pdf. Acesso em: 19 de maio de 2021.
Machine Learning é um subconjunto da inteligência artificial focado na construção de aplicações que aprendem com os dados e melhoram sua precisão ao longo do tempo, sem, contudo, serem programadas para isso. Assim, a máquina é treinada para aprender com a sua experiência anterior, encontrando padrões e recursos em meio a grandes quantidades de dados a fim de tomar decisões e fazer previsões com base em novos dados.
Atualmente, o aprendizado de máquina está expressivamente ao nosso redor: desde detectores de spam em nossos e-mails até a análise de curvas de declínio, por exemplo. Dessa forma, ele se torna importante porque, à medida que o volume de dados aumenta, a cognição humana não acompanha e, portanto, não é mais capaz de decifrar informações importantes desses dados por meio de técnicas convencionais – por exemplo, quando é necessário analisar dados de 5 ou 10 poços em oposição a 1000 ou 2000 poços.
Nesse contexto, é possível distinguir quatro classificações de machine learning:
Além disso, é possível diferenciar as etapas para construir um modelo de machine learning. De forma simples, elas podem ser divididas em:
Etapa 1: coleta de dados;
Etapa 2: limpeza de dados;
Etapa 3: análise de dados de treinamento; normalização/padronização.
Essas 3 primeiras etapas incluem detecção de anomalias, remoção de colinearidade e classificação e seleção de recursos. Após esta “preparação de dados”, começa-se a trabalhar no/com o próprio algoritmo.
Etapa 4: treinar o conjunto de dados com base em vários algoritmos;
Etapa 5: normalizar os dados de teste;
Etapa 6: testar o algoritmo em vários conjuntos cegos;
Etapa 7: aplicar e usar o algoritmo.
Ainda, uma 8ª etapa pode ser mencionada se levarmos em consideração a melhoria do algoritmo ao longo do tempo.
Podemos, dessa forma, destacar dois modelos de machine learning: clustering k-means e as redes neurais artificiais.
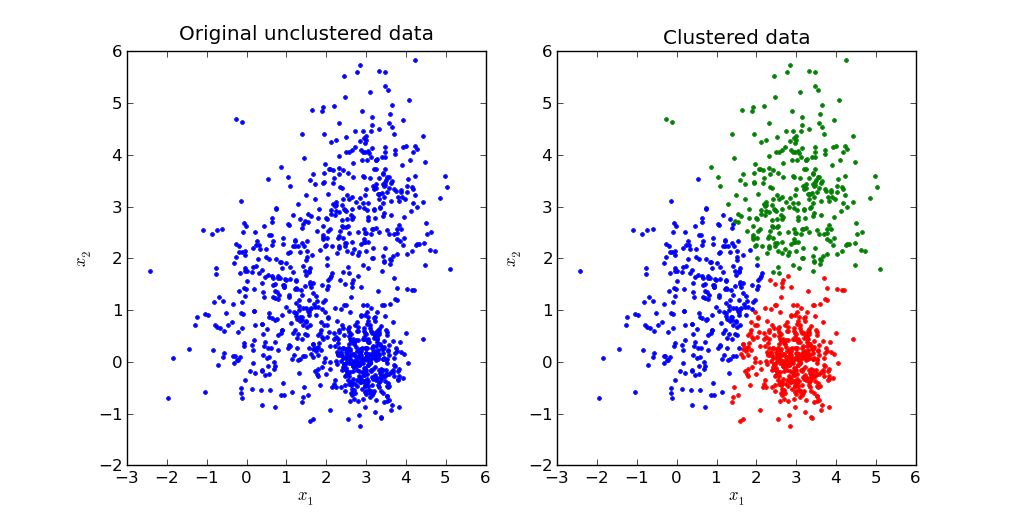
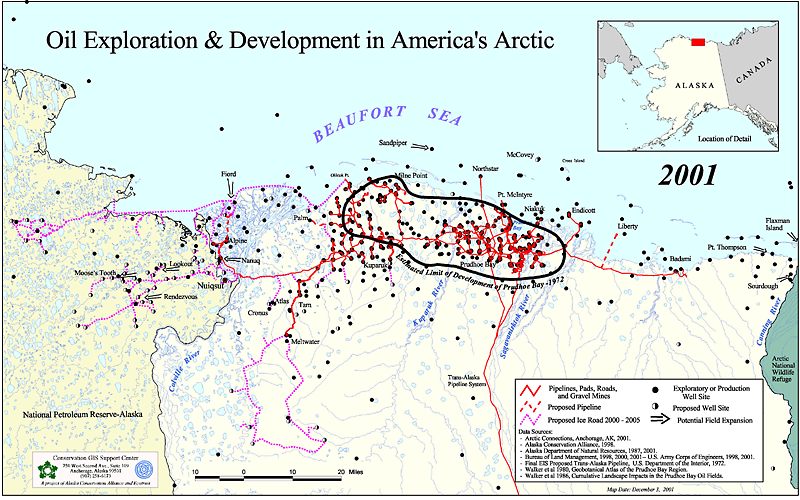
Algumas aplicações já existem e são visíveis na indústria do petróleo quando se considera o machine learning. Por exemplo, o campo Prudhoe Bay, descoberto na década de 60 e localizado no Alasca, possui uma rede gigantesca com mais de oitocentos (800) poços produtores, com estações separadoras trifásicas e outros equipamentos de grande porte. Nesse campo, a análise de cluster foi utilizada em associação com uma Rede Neural Artificial (RNA) para determinar a estação dos compressores ideais, para diferentes vazões, uma vez que a Razão Óleo-Gás (RGO) é uma variável limitante do sistema.
Por fim, é importante notar que a indústria de óleo e gás gera grandes quantidades de dados todos os dias. Portanto, podemos ver a aplicação potencial de machine learning, transformando muitos dos dados coletados em insights úteis e valiosos que ajudarão no processo de tomada de decisões. Portanto, é possível otimizar as operações a fim de gerenciar os riscos e desvantagens, minimizar custos e maximizar lucros.
Por Maria Pedrosa
Referências
BELYADI, H. Practical Machine Learning Applications in the Oil and Gas Industry. 2020. Disponível em: <https://www.youtube.com/watch?v=GKuntogLubI&t=1787s>.
PECZEK, M. P. P.; CANTUÁRIA, M. A. G.; FERREIRA, G. S. A Transformação digital e seu impacto na indústria de óleo e gás e na formação em Engenharia de Petróleo: um panorama. COBENGE, Fortaleza, 2019.
TOWARDS DATA SCIENCE. K-Means Data Clustering. 2017. Disponível em: <https://towardsdatascience.com/k-means-data-clustering-bce3335d2203>.
YUNLAI, Y.; APLIN, A. C.; LARTER, S. R. Quantitative assessment of mudstone lithology using geophysical wireline logs and artificial neural networks. 2004.
Quando se busca sobre tratamento de dados estatísticos, há uma ampla oferta de recursos associados a esta demanda em escala mundial. Podem ser citadas como exemplo as linguagens de programação (C, C++, Java, Python, etc.) e também softwares (SAS, R, MATLAB, Orange, etc.), com cada um possuindo pontos fortes e fracos dependendo da aplicação. Particularmente, entre esses, há um destaque para o Python e o R, que tem apresentado um grande aumento em popularidade e aplicações nos últimos anos. O intuito deste texto é mostrar uma visão geral sobre o potencial de ambos os recursos, justificando o crescimento visualizado e servindo como motivação para a exploração dos mesmos independente do ambiente de trabalho.
R se trata de um software com um ambiente de trabalho feito para lidar com estatística computacional e com linguagens de programação gráficas. Ele possui licença aberta sobre os termos GNU (General Public License) e é amplamente utilizado nos mais diversos setores, seja no âmbito empresarial, acadêmico ou científico. (ALKARKHI; ALQARAGHULI, 2020). Além disso, existe ainda uma série de pontos que o tornam atrativo, dentre os quais:
A seguir, é mostrado algumas figuras que ilustram um pouco do que foi tratado, no caso a interface com acesso a ajuda e um início de experimentação. Todos esses recursos dão um suporte sólido para os iniciantes, em paralelo a um ambiente que tem ficado cada vez mais robusto para os usuários avançados, instigando aos usuários que estão começando o aprendizado a explorar o software.
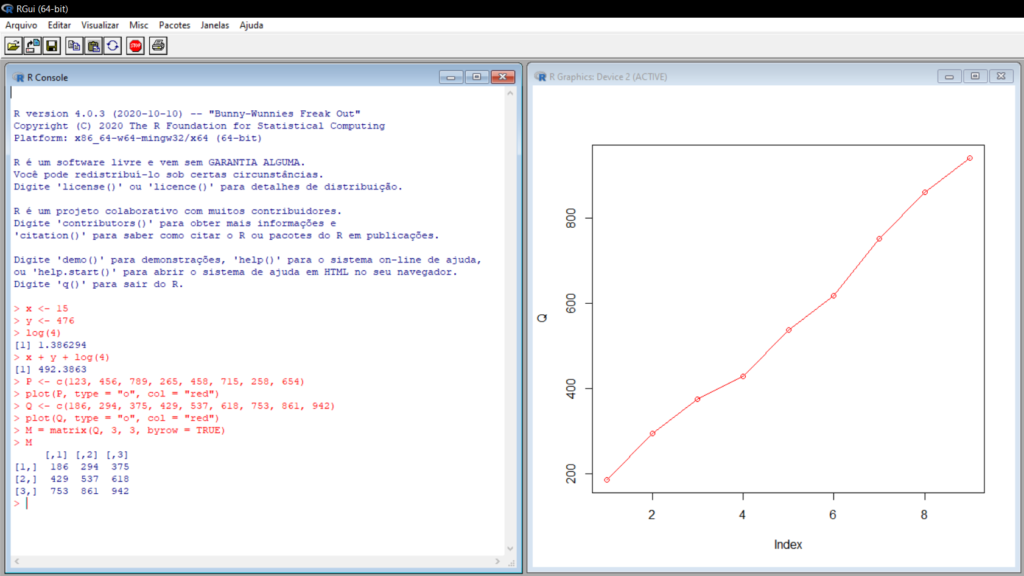
As interações foram feitas de forma natural, a soma foi realizada diretamente, a função logarítmica foi escrita da forma que vemos nos livros, a plotagem do gráfico foi rápida com o auxílio de uma das funções built-in do R e quando houve erro no argumento o programa avisou e por último, a matriz construída também foi com auxílio de outra função built-in, tudo muito intuitivo.
Agora, apresenta-se o Python, que se trata de uma linguagem de programação focada na eficiência e produtividade no desenvolvimento e resolução de problemas de interesse. Em vários rankings, se aponta essa como uma das 5 mais populares do mundo (MUELLER, 2018). Também há diversos recursos que a fazem se destacar comparada às demais, entre esses estão:
Também será mostrado logo a frente um pouco da interface, de forma a explicitar para novos usuários como os primeiros comandos são intuitivos assim como o acesso a ajuda do ambiente.
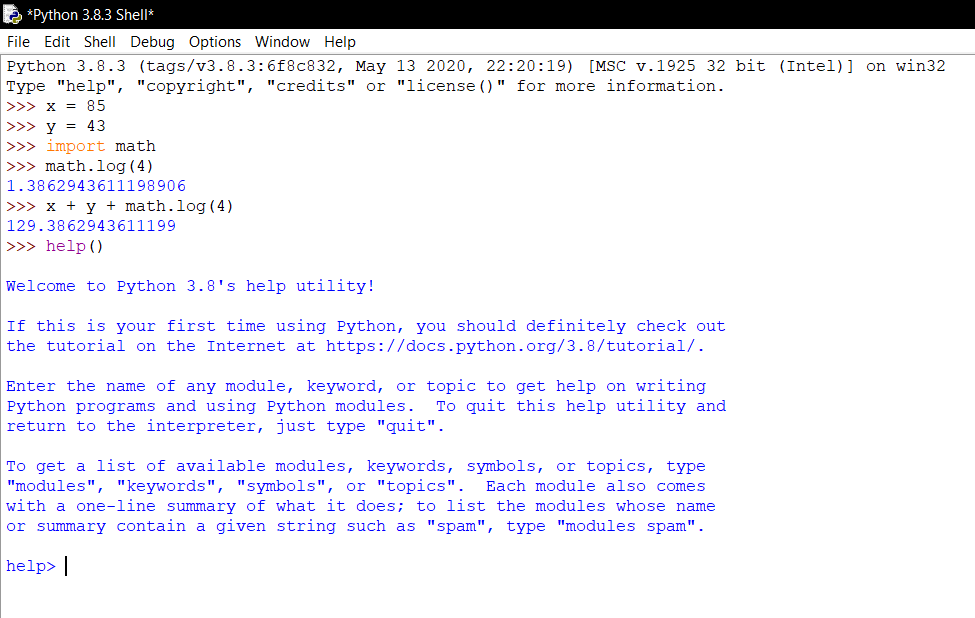
Nessa figura, foram feitas apenas 3 interações iniciais e já se pode observar alguns detalhes didáticos da ferramenta, por exemplo:
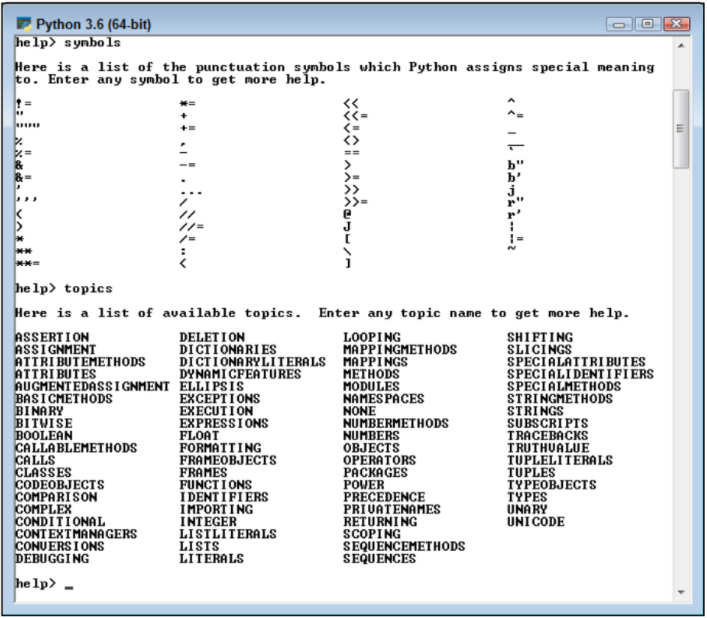
Após o exposto, conclui-se que mesmo com uma apresentação de visão geral, já há motivos que de fato tornam as ferramentas atraentes para as mais diversas aplicações, mostrando que faz sentido que elas tenham crescido em popularidade nos últimos anos. Fica como consideração final a reflexão sobre o quanto poderia ser explorado caso houvesse domínio das duas ferramentas simultaneamente, visto o potencial de ambas.
Referências:
ALKARKHI, A. F. M.; ALQARAGHULI, W. A. A. Applied Statistics For Environmental Science With R. 1. ed. Amsterdam: Joe Hayton, 2020.
MUELLER, J. P. Beginning Programming with Python ® For Dummies ®. 2. ed. New Jersey: John Wiley & Sons, Inc., 2018.
SANDER, C. TOP 7 ferramentas para análise de dados empresariais. [s.l]. 7 Dez, 2018. Disponível em: https://caetreinamentos.com.br/blog/ferramentas/ferramentas-para-analise-dados/. Acesso em: 09 Jan, 2021.
Autor: Messias Gutemberg.
No post anterior, discutimos sobre como é obtida a espessura de um reservatório. Agora, ainda seguindo a linha da petrofísica, vamos abordar como são obtidas mais duas propriedades essenciais deste campo.
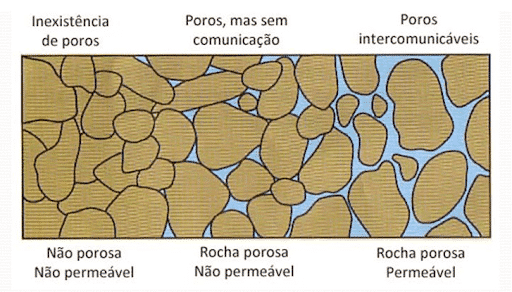
A porosidade pode ser definida como a capacidade de armazenamento de fluidos de uma rocha. É representada pela relação entre o volume de espaço poroso de uma rocha e o volume total desta, expresso em porcentagem. Ela é dividida em dois subtipos, no caso: a porosidade primária, que é decorrente da deposição formadora da rocha (como por exemplo a porosidade intergranular dos arenitos) e a secundária, que é resultante de processos geológicos que ocorreram depois da conversão dos sedimentos em rochas (como por exemplo o desenvolvimento de cavidades devido a dissolução em calcários).
Os principais fatores que influenciam a porosidade podem ser divididos por litologia. Para os arenitos são: grau de seleção, irregularidade e arranjo dos grãos, cimentação, compactação e conteúdo de argila. Enquanto para os carbonatos são: dissolução, cimentação, conteúdo de matriz e dolomitização.

A seguir, temos a permeabilidade, que pode ser definida como a capacidade de fluxo de fluidos em um meio poroso. Pode ser subdividida essencialmente em dois tipos: a permeabilidade absoluta, que mede essa capacidade em um meio 100% saturado com um único fluido e a permeabilidade relativa, onde a medição é feita na presença de mais de um fluido. A vazão do fluido obedece a lei de Darcy e outra observação importante é que ela é uma propriedade anisotrópica, ou seja, depende da direção de medição.
Após a definição, falando propriamente da obtenção desses parâmetros, eles tem uma importância vital porque a taxa, a distribuição da porosidade, a permeabilidade e a saturação são responsáveis por ditar o desenvolvimento do reservatório e os planos de produção, pois definem o volume final de hidrocarbonetos que pode estar presente na rocha.
A porosidade pode ser obtida de duas formas, direta e indireta. Primeiramente, é possível realizar a determinação direta caso haja uma amostra não danificada do reservatório a ser analisado. Imagens de tomografia e exames de microscópio eletrônico podem verificar se o contato dos grãos está intacto, os revestimentos dos poros não estão danificados e os fluidos de perfuração pesados e/ou partículas estão ausentes, confirmando a integridade da amostra.
Existem muitas armadilhas que podem danificar a amostra. Uma delas é a limpeza dessa amostra de salmoura e óleo bruto, que deve ser feita de forma completa e com delicadeza, tendo em vista que tudo deve ser retirado sem danificar o mineral. Novos poros não podem ser criados durante o processo de limpeza. Outra armadilha para evitar é que algumas amostras de rocha são mecanicamente fracas e não compactadas, uma vez livre da sobrecarga, quando trazidas para a superfície. Sendo, então, necessário aplicar as condições originais de tensão na amostra, para obter um resultado verídico.
Em contrapartida, sobre a obtenção indireta, pode ser abordado por litologia. Para o caso de areias, o perfil de densidade é o método mais preciso quando se tem o conhecimento da densidade do grão e do fluido, sendo muito utilizado em poços de produção. Entretanto tais parâmetros não costumam ser conhecidos em poços pioneiros. Nesses poços há quatro incógnitas: a densidade do grão, pois essa pode mudar ao longo do poço conforme a litologia muda, a saturação de hidrocarbonetos, a saturação de água e a porosidade, e somente uma medição: a densidade aparente. Nesse caso, um método estatístico seria usado para combinar as leituras do perfil de densidade, acústico, neutrônico, e de raio gama para resolver as incógnitas. Já para os carbonatos, a determinação da porosidade é geralmente simples, a não ser quando há na rocha uma grande cavidade ou fraturas. Gráficos de nêutron – densidade e nêutron – acústico têm se mostrado úteis e precisos nas suas medições.
Agora, temos também a obtenção da permeabilidade, onde são aplicadas técnicas que possam representar toda a extensão do reservatório. As principais são duas: A primeira opção se trata do uso de amostras da parede do poço. Esta técnica é válida para arenitos pouco ou não consolidados. Os carbonatos costumam ser muito heterogêneos, e pequenas amostras não são o suficiente para fornecer qualquer informação sobre a permeabilidade do reservatório. Não é possível medir a permeabilidade de forma direta, pois as amostras de arenito são naturalmente contaminadas por lama de perfuração. Entretanto, é possível inspecionar a amostra de rocha por meio de um microscópio binocular para estimar o tamanho médio de grão, classificação e grau de consolidação e preenchimento dos poros. Com essa informação, fica viável calcular a permeabilidade.
E por fim, a segunda opção é a utilização dos perfis de ressonância magnética nuclear (RMN). A interpretação das respostas do perfil de ressonância magnética nuclear fornece uma distribuição volumétrica do tamanho dos poros. Dependendo do formato dos poros, um valor de permeabilidade poderá ser calculado.
Referências:
Edward D. Holstein. Petroleum Engineering Handbook, Vol. 5 – Reservoir Engineering and Petrophysics. Society of Petroleum Engineers, 2007.
Ellis, D. V. & Singer, J. M. Well logging for Earth Scientists. Springer-Verlag., 2007.
Rider, M. H., The Geological Interpretation of Well logs. Gulf Publishing, 1996.
Schlumberger, Anne. The Schlumberger Adventure. 1982.
Schlumberger. Log Interpretation. Principles/Applications. 1989.
Tittmam, J. Geophysical Well logging. Academic Press Inc., 1986.
Autor: Maria Eduarda Melentovytch Ribeiro de Castro
Por definição, petrofísica é o estudo das propriedades físicas das rochas e dos fluidos contidos nestas, enfatizando as associadas ao sistema de poros, distribuição de fluidos e características de fluxo. A forma como essas especificidades se relacionam é usada para determinar e avaliar reservas e fontes de hidrocarbonetos ou aquíferos.
De maneira geral, as características do reservatório a serem encontradas são a espessura, litologia, porosidade, permeabilidade e o fluxo fracionário (gás, óleo e água) enquanto as determinações relevantes ligadas aos fluidos são identificação, caracterização, saturação e pressão. Dentre todas, aqui destacaremos a espessura, abordando algumas formas de encontrar este parâmetro.

A espessura e os limites do reservatório são, geralmente, as propriedades mais fáceis de se medir. Por convenção, quando medida em pés, a medida é arredondada até o pé mais próximo, quando medido em metros é arredondado para 0,1 m mais próximo. A forma como a medida é feita depende da litologia.
Para areias (termo usado em geral para se referir a arenitos ou a rochas clásticas sedimentares) e xistos (geralmente associado a rochas metamórficas), usa-se o perfil de raio gama para identificá-las, já que essas litologias possuem um comportamento diferente em relação a radiação gama. O ponto de inflexão da taxa de contagem do raio gama em unidades API representa o limite entre camadas.
Entretanto, é importante ressaltar que se a camada de areia apresentar uma certa quantidade de mica, detritos vulcânicos e/ou feldspato de potássio, ela pode apresentar tanta radiação quanto o xisto, sendo assim difícil de separá-los por meio da radiação gama. Nesse caso, quando o poço foi perfurado com lama a base d’água, utiliza-se o método do potencial espontâneo (SP). Este é um método de campo natural que baseia-se no fato de que, na ausência de um campo elétrico artificial, é possível medir uma diferença de potencial entre dois eletrodos introduzidos no terreno. Porém caso o ambiente tenha pouca porosidade e uma alta resistividade o SP é suprimido e não é um bom indicador.
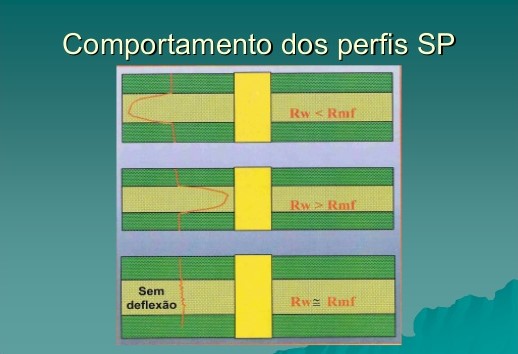
Ademais, outra ferramenta que pode ser usada através da condutividade e resistividade é o perfil de indução, que é utilizado quando a perfuração é feita com lama a base óleo (ou em casos especiais onde a lama base água tem baixa salinidade). Diferente do perfil SP, o indução é o mais indicado para lamas com alta resistividade.
Consta de um Transmissor coaxial ao eixo do poço onde uma corrente alternada de alta frequência (20 KHz) gera um campo eletromagnético (CMp) perpendicular na formação. A componente vertical do CMp vai induzir uma corrente na formação, já que os poros preenchidos por soluções eletrolíticas, agem como se fossem infinitos “fios elétricos” interligados, formando uma bobina de rocha. Estas correntes vão criar um campo magnético secundário, o qual vai induzir uma corrente na bobina receptora e finalmente ser registrado.

Concluindo, uma ressalva importante é sobre a litologia de carbonatos, que no caso, é necessário usar uma perfilagem que seja sensível a porosidade como por exemplo a sônica. O funcionamento desta é baseado na medição do tempo de trânsito de ondas sísmicas que se propagam através da lama de perfuração e das rochas.

Referências:
Edward D. Holstein. Petroleum Engineering Handbook, Vol. 5 – Reservoir Engineering and Petrophysics. Society of Petroleum Engineers, 2007.
Ellis, D. V. & Singer, J. M. Well logging for Earth Scientists. Springer-Verlag., 2007.
Rider, M. H., The Geological Interpretation of Well logs. Gulf Publishing, 1996.
Schlumberger, Anne. The Schlumberger Adventure. 1982.
Schlumberger. Log Interpretation. Principles/Applications. 1989.
Tittmam, J. Geophysical Well logging. Academic Press Inc., 1986.
Autor: Maria Eduarda Melentovytch Ribeiro de Castro
Você sabia que o processo seletivo do PetroPET passou por uma transformação e agora está totalmente diferente? Isso mesmo!
Já não é mais novidade pra ninguém que o momento em que estamos tem nos levado a constantes adaptações e, pensando exatamente nisso, a nossa equipe decidiu reformular completamente nosso processo seletivo, tornando-o muito mais prático, direto e imersivo.
Desta maneira, é com muito prazer que anunciamos as novas etapas do novo processo seletivo:





Fique ligado nas nossas redes sociais para acompanhar novas informações e entre em contato com a nossa equipe em caso de dúvida ou acesse o link na nossa bio do Instagram!
Venha nos ajudar a desenvolver o meio acadêmico!
O PetroPET está envolto a três pilares que faz com que seus membros desenvolvam atividades ao redor desses que são: Pesquisa, Extensão e Ensino.

São enfatizadas as prioridades de pesquisa, bem como as metodologias de produção de conhecimento (já existentes ou inovadoras) e avaliação crítica de resultados. Nesse contexto, o grupo preza pela compreensão dos principais desafios existentes no cenário atual da indústria de petróleo, buscando realizar projetos em áreas de alta relevância para o setor, tais como: Transformação Digital, Análise de Decisão e Integridade de Poços.

Extensão Universitária é a comunicação que se estabelece entre universidade e sociedade visando à produção de conhecimentos e à interlocução das atividades acadêmicas de ensino e de pesquisa, através de processos ativos de formação.
A Extensão engloba experiências de popularização da ciência, e realiza atividades que favorecem a construção de caminhos que podem contribuir no enfrentamento de problemas e questões sociais. Exercidas como direito social, as práticas extensionistas primam pelo respeito à diversidade cultural e têm como eixo o encontro entre os saberes acadêmicos e os saberes espontâneos.

Os projetos do PET voltados para o pilar do Ensino visam, antes de tudo, a difusão e promoção de conhecimento, seja prático ou teórico, a respeito do âmbito de óleo e gás ou engenharia como um todo, além de buscar criar a oportunidades de aproximação entre alunos de diferentes períodos e estreitar as relações docente discente.
Um exemplo da atuação da equipe sob esse viés é a PetroUFF, que tem como propósito qualificar os alunos, principalmente, das áreas de Engenharia, Geofísica e Geologia, buscando oferecer conhecimento extra ao que o curso de graduação disponibiliza, ajudando, desse modo, a complementar a formação profissional dos mesmos. Esse complemento se dará não apenas na área técnica, mas também no âmbito das habilidades denominadas Soft Skills.
Além disso, vale lembrar também que a produção de conteúdo semanal sobre a área de O&G realizada no site do PetroPET e compartilhamento de atividades da equipe nas páginas do Instagram e Facebook também são caracterizados como atividades guiadas sob o viés do Ensino, uma vez que visam continuamente fazer com que os conhecimentos sobre o mundo do petróleo alcancem o maior número de pessoas possível.
Estávamos ansiosos para esse momento e ele finalmente chegou!
Você que é apaixonado pelo mundo do petróleo, gosta de trabalhar em equipe e se identifica com os nossos três pilares, fique atento a nossas redes sociais pois as inscrições para o processo seletivo do PetroPET começarão no dia 26/10.
Buscamos alunos que entraram em 2019.1 ou antes, mas se você entrou em 2020.1 e tem vontade de participar entre em contato conosco!
Lembrando que o nosso objetivo é a institucionalização de um ambiente interativo para todos os alunos, um meio no qual seja possível a criação e desenvolvimento de grupos de aprendizagem com o aprimoramento e a diversificação da formação acadêmica, ética e técnica dos alunos participantes.
Venha nos ajudar a desenvolver o meio acadêmico!
No dia 23/09/2020, o Grupo PetroPET – Engenharia de Petróleo teve uma capacitação com a ex-membra do PET e Engenheira de Petróleo, Ísis Ladeira, que participou da primeira leva de alunos do Grupo.
Os membros atuais puderam aprender um pouco sobre o Design Thinking.
Você sabe o que é?
É o conjunto de ideias e insights para abordar problemas, relacionados a futuras aquisições de informações, análise de conhecimento e propostas de soluções. Como uma abordagem, é considerada a capacidade para combinar empatia em um contexto de um problema, de forma a colocar as pessoas no centro do desenvolvimento de um projeto; criatividade para geração de soluções e razão para analisar e adaptar as soluções para o contexto.
Foi um momento muito inovador e proveitoso.
Se você está interessado no que o PetroPET está fazendo e gostaria de fazer parte do mesmo, fique atento às nossas redes sociais que em breve teremos novidade.











