Machine Learning: aplicações práticas na indústria de petróleo
Machine Learning é um subconjunto da inteligência artificial focado na construção de aplicações que aprendem com os dados e melhoram sua precisão ao longo do tempo, sem, contudo, serem programadas para isso. Assim, a máquina é treinada para aprender com a sua experiência anterior, encontrando padrões e recursos em meio a grandes quantidades de dados a fim de tomar decisões e fazer previsões com base em novos dados.
Atualmente, o aprendizado de máquina está expressivamente ao nosso redor: desde detectores de spam em nossos e-mails até a análise de curvas de declínio, por exemplo. Dessa forma, ele se torna importante porque, à medida que o volume de dados aumenta, a cognição humana não acompanha e, portanto, não é mais capaz de decifrar informações importantes desses dados por meio de técnicas convencionais – por exemplo, quando é necessário analisar dados de 5 ou 10 poços em oposição a 1000 ou 2000 poços.
Nesse contexto, é possível distinguir quatro classificações de machine learning:
Aprendizagem Supervisionada (modelos preditivos), que treina a si mesma em um conjunto de dados rotulados. Isso significa que ela consiste em uma variável de destino/resultado (ou variável dependente) que deve ser prevista a partir de um determinado conjunto de preditores ou variáveis de entrada (também chamadas de variáveis independentes). Ademais, a aprendizagem supervisionada requer menos dados de treinamento do que os demais métodos, tornando o aprendizado mais fácil uma vez que os resultados do modelo podem ser comparados aos resultados reais. Exemplos desse método são as redes neurais artificiais e as árvores de decisão.
Aprendizagem não supervisionada (modelos descritivos), que insere (muitos) dados não rotulados sem destino ou variável de resultado para prever/estimar, de modo que extraem-se recursos significativos necessários para rotular, ordenar e classificar os dados em tempo real e sem intervenção humana. Isso significa que esse método é usado para agrupar dados em grupos diferentes. Consequentemente, a aprendizagem não supervisionada tem menos a ver com a automação de decisões e previsões e mais com a identificação de padrões e relações em dados que a análise humana não seria capaz. Exemplos desse método incluem clustering k-means e hierárquico.
Aprendizagem semi supervisionada, que encontra-se no meio, como uma mistura dos dois tipos de aprendizagem. Neste caso, o modelo geralmente começa como não supervisionado, para agrupar os dados, e, então, os dados agrupados tornam-se a saída para seu aprendizado supervisionado. Abordagens heurísticas são um exemplo desse método.
Aprendizagem de reforço, que é um modelo comportamental de machine learning, semelhante ao aprendizado supervisionado, mas no qual a máquina se treina continuamente por tentativa e erro. Uma sequência de resultados bem-sucedidos será reforçada para desenvolver a melhor recomendação ou política para um determinado problema. Para esse método, podemos apontar o Q-learning como exemplo.
Além disso, é possível diferenciar as etapas para construir um modelo de machine learning. De forma simples, elas podem ser divididas em:
Etapa 1: coleta de dados;
Etapa 2: limpeza de dados;
Etapa 3: análise de dados de treinamento; normalização/padronização.
Essas 3 primeiras etapas incluem detecção de anomalias, remoção de colinearidade e classificação e seleção de recursos. Após esta “preparação de dados”, começa-se a trabalhar no/com o próprio algoritmo.
Etapa 4: treinar o conjunto de dados com base em vários algoritmos;
Etapa 5: normalizar os dados de teste;
Etapa 6: testar o algoritmo em vários conjuntos cegos;
Etapa 7: aplicar e usar o algoritmo.
Ainda, uma 8ª etapa pode ser mencionada se levarmos em consideração a melhoria do algoritmo ao longo do tempo.
Podemos, dessa forma, destacar dois modelos de machine learning: clustering k-means e as redes neurais artificiais.
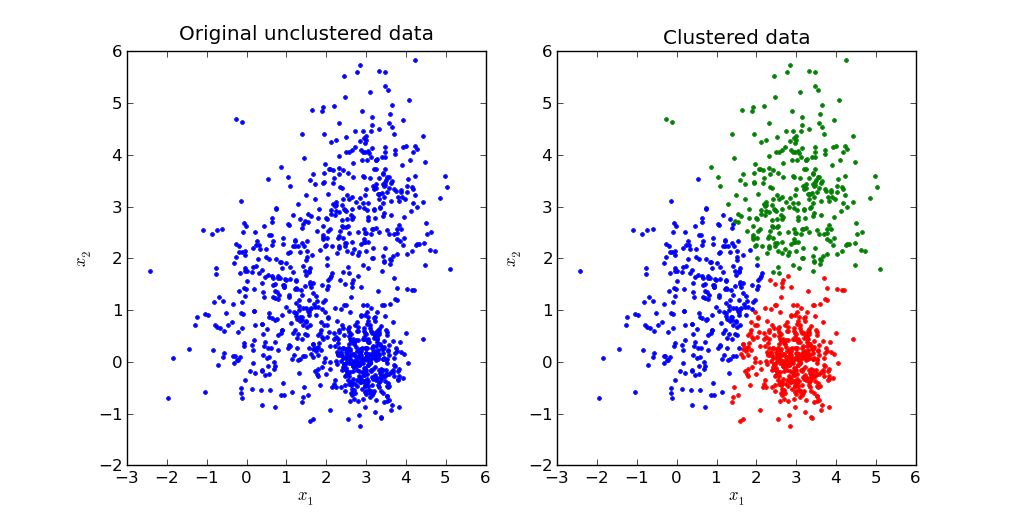
Clustering k-means é um dos algoritmos de machine learning não supervisionado mais usados para análise de clustering e é uma técnica simples e fácil usada para classificar ou agrupar um conjunto de dados em um certo número de clusters. Essa técnica começa com a atribuição do número de clusters a serem encontrados. Os pontos que representarão os centróides desses clusters são, então, uniformemente dispersos pelos dados e movidos como se por gravidade até que se acomodem em posições nas nuvens de dados e parem de se mover. Algumas aplicações de clustering por k-means na indústria de óleo e gás são detecção de carga líquida e clustering de curvas de tipo.
Fonte: K-Means Data Clustering; towards data science (2017).
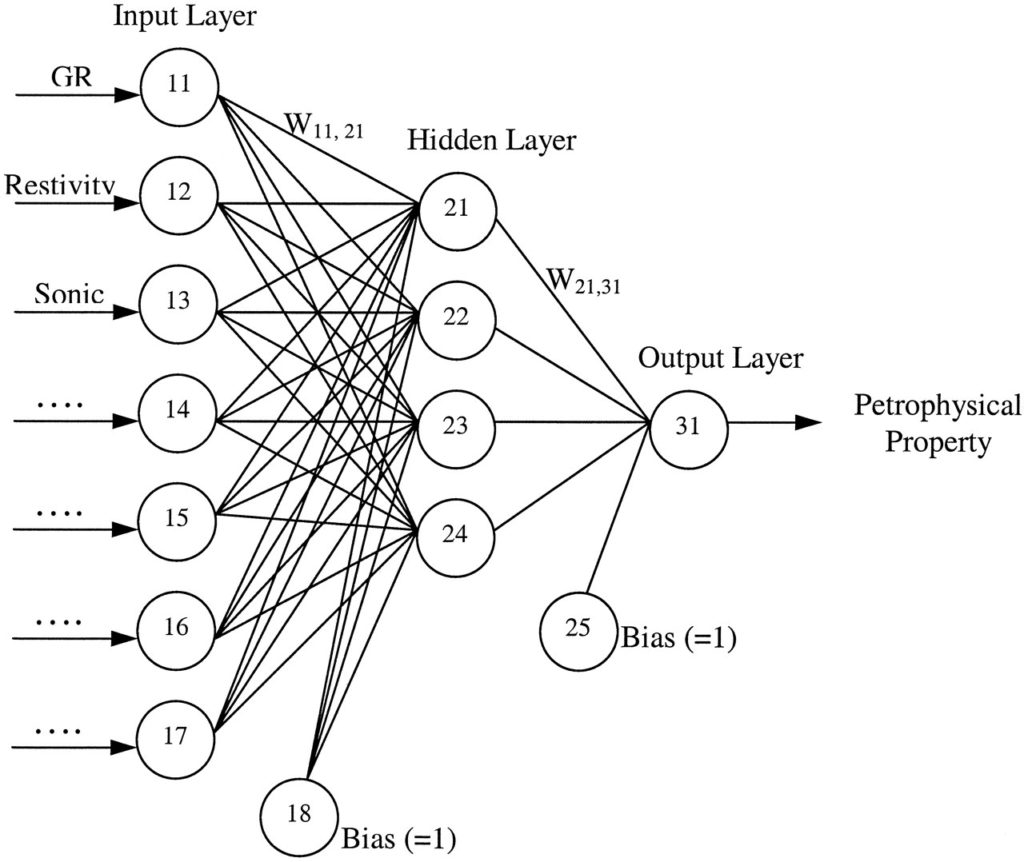
As redes neurais artificiais, por sua vez, foram desenvolvidas para imitar algumas das operações dos neurônios em um cérebro, que são conceitualmente interconectados por vários caminhos conectados com “interruptores liga-desliga” para emular as sinapses do cérebro. Cada rede neural artificial consiste em uma camada de entrada, uma ou mais camadas ocultas e uma de saída. O número de neurônios (elementos de processamento) nas camadas de saída e de entrada é escolhido com base na natureza do problema a ser resolvido e nas propriedades que serão previstas. Quanto mais complexo for o problema, maior será o número de neurônios e camadas ocultas necessárias. Exemplos de aplicação de RNA em campos petrolíferos incluem processamento sísmico, mapeamento geológico e análise petrofísica.
Fonte: Quantitative assessment of mudstone lithology using geophysical wireline logs and artificial neural networks; Yunlai Yang, Andrew C. Aplin and Steve R. Larter (2004).
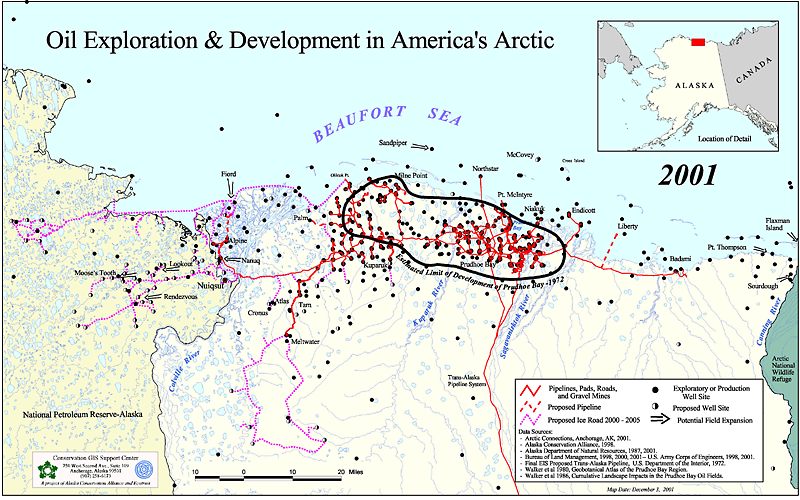
Algumas aplicações já existem e são visíveis na indústria do petróleo quando se considera o machine learning. Por exemplo, o campo Prudhoe Bay, descoberto na década de 60 e localizado no Alasca, possui uma rede gigantesca com mais de oitocentos (800) poços produtores, com estações separadoras trifásicas e outros equipamentos de grande porte. Nesse campo, a análise de cluster foi utilizada em associação com uma Rede Neural Artificial (RNA) para determinar a estação dos compressores ideais, para diferentes vazões, uma vez que a Razão Óleo-Gás (RGO) é uma variável limitante do sistema.
Fonte: Peczek et al; A Transformação digital e seu impacto na indústria de óleo e gás e na formação em Engenharia de Petróleo: um panorama (2019).
Por fim, é importante notar que a indústria de óleo e gás gera grandes quantidades de dados todos os dias. Portanto, podemos ver a aplicação potencial de machine learning, transformando muitos dos dados coletados em insights úteis e valiosos que ajudarão no processo de tomada de decisões. Portanto, é possível otimizar as operações a fim de gerenciar os riscos e desvantagens, minimizar custos e maximizar lucros.
Por Maria Pedrosa
Referências
BELYADI, H. Practical Machine Learning Applications in the Oil and Gas Industry. 2020. Disponível em: <https://www.youtube.com/watch?v=GKuntogLubI&t=1787s>.
PECZEK, M. P. P.; CANTUÁRIA, M. A. G.; FERREIRA, G. S. A Transformação digital e seu impacto na indústria de óleo e gás e na formação em Engenharia de Petróleo: um panorama. COBENGE, Fortaleza, 2019.
TOWARDS DATA SCIENCE. K-Means Data Clustering. 2017. Disponível em: <https://towardsdatascience.com/k-means-data-clustering-bce3335d2203>.
YUNLAI, Y.; APLIN, A. C.; LARTER, S. R. Quantitative assessment of mudstone lithology using geophysical wireline logs and artificial neural networks. 2004.
Endereço
Universidade Federal Fluminense, Escola de Engenharia, TEQ – Departamento de Engenharia Química e de Petróleo, Rua Passos da Pátria, 156 – Bloco D – Sala 264, 21.210-240 – Niterói – RJ.
Copyright 2026 - STI - Todos os direitos reservados